• Paper: https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf
• Demo: https://seamless. metademolab.com/
• Code: https://github.com/facebookresearch/seamless_communication
• Hugging Face: https://huggingface.co/spaces/facebook/seamless_m4t
Motivation
The idea in Babel Fish was to create a tool that could help individuals translate between any two languages. Previous Research Although text models have made significant breakthroughs in machine translation, with coverage expanding to more than 200 languages, speech-to-speech translation models have yet to make similar progress. Next, the article points out that traditional speech-to-speech translation systems rely on cascade systems, with multiple subsystems performing translation step by step, making it difficult to implement a unified scalable high-performance speech translation system. In order to fill these gaps, the author of this paper proposes SeamlessM4T (Large-Scale Multilingual and Multimodal Machine Translation), a large model for integrated speech-to-speech translation.
Method
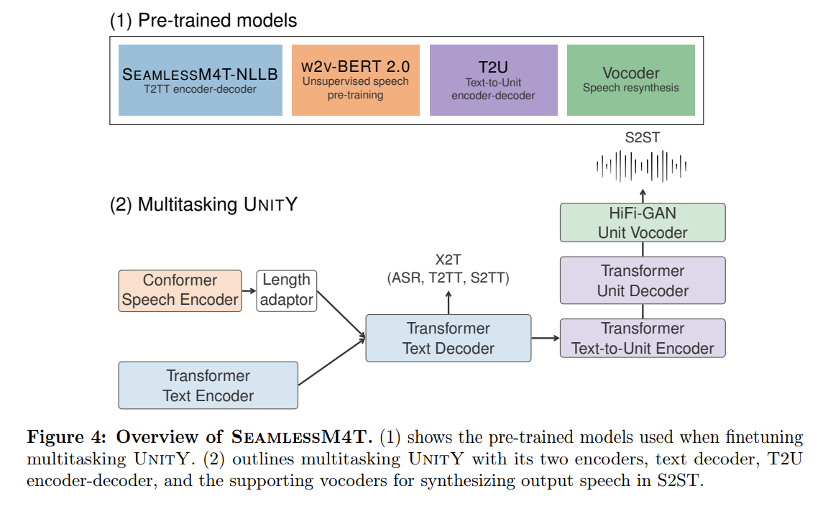
Figure 4 provides an overview of the SEAMLESSM4T model, including its four building blocks: (1) SEAMLESSM4T-NLLB, a large-scale multilingual T2TT model, (2) W2-BERT 2.0, a speech representation learning utilizing unlabeled speech audio data Model. (3) T2U text-to-unit sequence-to-sequence model, and (4) multilingual HiFi-GAN unit vocoder for synthesizing speech from units. The SEAMLESSM4T multi-tasking UNITY model integrates components of the first three building blocks and is fine-tuned in three stages, starting with the X2T model with only English targets (1,2), to the full-fledged multi-tasking UNITY (12,3) The system ends executing T2TT, S2TT, S2ST and ASR.
Unsupervised speech pre-training
Labels for speech recognition and translation tasks are scarce and expensive, especially for resource-poor languages. Training challenging speech translation models with limited supervision. Therefore, self-supervised pre-training using unlabeled speech data is a practical way to reduce the need for supervision in model training. This approach helps achieve the same recognition and translation quality with less labeled data compared to pre-trained models. It also helps push the limits of model performance using the same amount of labeled data. The latest and most publically advanced multilingual speech pre-model is proposed by MMS Pratap et al., which extends its predecessor (XLS-R Babu et al., 2022), adding 55K hours of data training, and more than 1300 topics. New language. In addition to MMS, USM Zhang et al., 2023 proposed a new generation of SOTA multilingual speech pre-training model, which utilizes the latest model architecture BEST-RO instead of wav2vec 2.0 and has the largest training data (12 million hours ), themes in more than 300 languages.
W2v-BERT 2.0 builds upon the foundation of w2v-BERT, as introduced by Chung et al. in 2021, by incorporating a combination of contrastive learning and masked prediction learning. This enhanced version further augments w2v-BERT with the inclusion of additional codebooks in its learning ives. The contrastive learning module within w2v-BERT 2.0 is employed to acquire Gumbel vector quantization (GVQ) codebooks and contextualized representations, which are subsequently utilized in the masked prediction learning module. In the latter module, the contextualized representations are refined through the unique task of directly predicting the GVQ codes, rather than the conventional approach of polarizing the prediction probabilities for correct and incorrect codes at the masked positions. Moreover, w2v-BERT 2.0 introduces a distinctive approach by incorporating two GVO codebooks for product quantization, in alignment with Baevski et al. (2021). The training ives for w2v-BERT 2.0 encompass the contrastive learning loss (L), mirroring that of w2y-BERT, alongside a codebook diversity loss to encourage uniform code utilization. Additionally, a masked prediction task utilizing random projection quantizers (RPO) has been introduced:
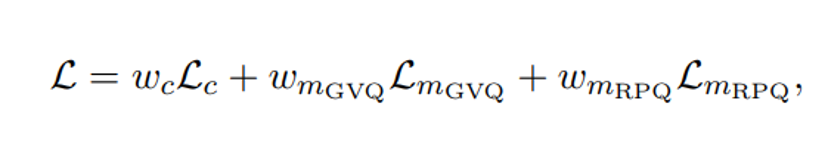
In terms of architecture, w2V-BERT 2.0 adheres to the w2v-BERT XL architecture (Chung et al., 2021) and serves as the pre-trained speech encoder in SEAMLESSM4T-LARGE. This encoder comprises 24 Conformer layers (Gulati et al., 2020) and boasts approximately 600 million model parameters. The training dataset for w2V-BERT 2.0 consists of a vast 1 million hours of open speech audio data, encompassing more than 143 languages.
X2T: Into-Text Translation and Transcription
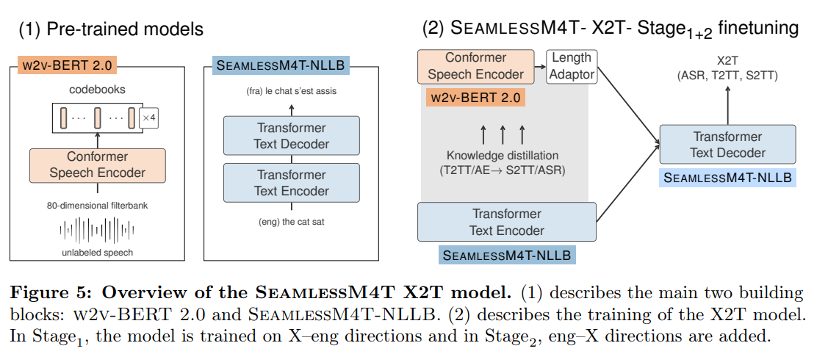
The core of our multi-task UnitY framework is the X2T model, a multi-encoder sequence-to-sequence model with one Conformer-based encoder for speech input and another Transformer-based encoder for text input— —Both are connected to the same text decoder. This article’s X2T model is trained on S2TT data, pairing source language speech audio with target language text.
Speech-to-Speech Translation
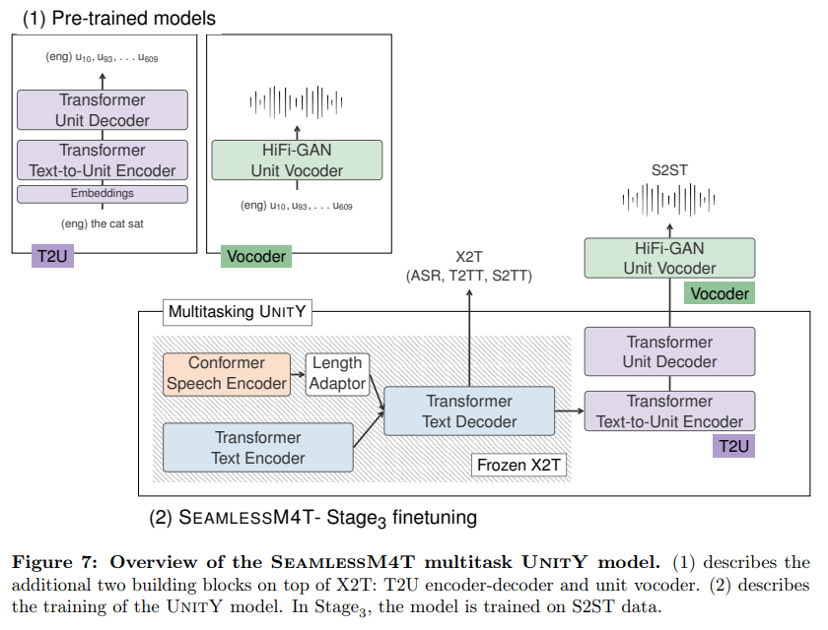
The key to the speech-to-speech translation model proposed in this paper is to use self-supervised discrete acoustic units to represent the target speech, thereby decomposing the S2ST problem into a speech-to-unit translation (S2UT) step and a unit-to-unit speech (U2S) conversion step. For S2UT, the SeamlessM4T model shown in Figure 4 uses UnitY as a two-pass decoding framework that first generates text and then predicts discrete acoustic units. Compared with the ordinary UnitY model, (1) the core S2TT model initialized from scratch is replaced by the pre-trained X2T model to jointly optimize T2TT, S2TT and ASR, (2) the shallow T2U model (in Inaguma et al. (called T2U unit encoder and second channel unit decoder) are replaced by a deeper Transformer- based encoder-decoder model with 6 Transformer layers s, (3) the T2U model is also trained on the T2U task rather than from scratch. X2T’s pre-training yields a more powerful speech encoder and higher-quality first-pass text decoder, while the scaling and pre-training of the T2U model enables this paper to better handle multi-language unit generation without interference.
Utilizing all the components listed in the previous sections, this article trained the SEAMLESSM4TLARGE model in the three stages outlined. SEAMLESSM4T-LARCE has 2.3B parameters and is fine-tuned on T2TT for 95 languages paired with English, on ASR for 96 languages, on S2TT for 89 languages paired with English, on S2ST has been fine-tuned for 95 English directions and 35 target languages in English. The amount of supervision data for each direction is detailed in Tables 35 and 36. This means that, for some source languages, our model will undergo zero-shot evaluation to achieve the 100-eng coverage described in Table 2. In order to provide a reasonably sized model, this paper follows the same approach as training SEAMLESSM4TMEDIUM. This model has 57% fewer parameters than SEAMLESSM4T-LARGE and is designed to be an accessible testbed for fine-tuning, improving or participating in the analysis. SEAMLESSM4T-MEDIUM has the same coverage as SEAMLESSM4T-LARGE but is built on smaller, more parameter-efficient components (see Figure 4). This article pre-trains a small ew2V-BERT 2.0 with 300M parameters and uses the distillation model (NLLB-600M-DISTILLED) of NLLB Team et al2022 to initialize the T2TT module of multi-task UNIrY. See Table 13 for a comparison between SEAMLESSM4T-LARGE and SEAMLESSM4T-MEDIUM.

Advantage
The proposed SeamlessM4T model has achieved significant improvements in multiple evaluation indicators, supports translation in multiple languages, and has better robustness and translation security. Through self-supervised learning and self-alignment, a machine translation system that supports multi-language and multi-modality is built, and significant performance improvements are achieved.
SeamlessM4T supports the following features:
• Automatic speech recognition in nearly 100 languages
• Speech-to-text translation for nearly 100 input and output languages
• Speech-to-speech translation for nearly 100 input languages and 35 (including English) output languages
• Text-to-text translation in nearly 100 languages
• Text-to-speech translation for nearly 100 input languages and 35 (including English) output languages
Speech translation falls short in coverage and performance compared to text translation. Current speech translation systems primarily translate other languages into English rather than from English. Speech is a richer medium than text, conveying more information through intonation, expression , and interaction, which makes speech translation challenging but also more natural and social. For many groups, such as those who are illiterate or visually impaired, speech is more accessible than text, and systems that can translate speech can promote inclusivity. For languages that use different scripts, speech translation avoids the problem of unintelligible output that may occur with text translation.
Current speech translation relies on a cascade system that combines automatic speech recognition (ASR), machine translation (MT), and text-to-speech synthesis (TTS) models in a chain. This can propagate errors and cause mismatches. This paper proposes a unified model SeamlessM4T that can handle ASR, speech-to-speech, speech-to-text, text-to-speech, and text-to-text translation. SeamlessM4T extends source and target language coverage, from 100 languages to English, and from English to 35 languages. Reaching new state-of-the-art performance in speech-to-text translation into English, achieving a 20% improvement in BLEU scores over previous models. The model is open-sourced, and the aligned speech data, mining tools, and other resources are also open-sourced to advance speech translation research.
Reference:
[1]SeamlessM4T—Massively Multilingual & Multimodal Machine Translation https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf





