
Since ChatGPT went live in November 2022, there has been a proliferation of large AI models. LLMs have quickly become a leading trend in AI, with major companies introducing various types of LLM, ranging from LLM, Foundational Models for speech, and multi-modal LLM. The remarkable performance and robustness of these models are truly awe-inspiring.
From the inception of AI, data, computational resources, and algorithms have been the cornerstones of AI development. Thanks to investments in data and computational resources, as well as algorithm optimizations, AI has become increasingly intelligent, meeting and exceeding expectations.
However, the ultimate goal of AI should not be limited to online chatting, voice communication, or artistic creation. To make AI better serve humanity, we need intelligent robots - AI-assisted smart robots. After all, we hope that humanity can receive better services, and the true culmination of AI lies in the creation of a multitude of intelligent robots capable of serving humans effectively.

Recently, Google's DeepMind has unveiled one of the world's largest universal LLMscalled RT-X. This model was trained by amalgamating robot training data from 33 top research labs worldwide. In addition to open-sourcing the code, the robot training dataset, Open X-Embodiment, has also been made available to the public. This marks a significant step in the open-sourcing of LLM, as previous releases only included code and models without sharing the data.
GitHub : https://robotics-transformer-x.github.io/
Paper : https://robotics-transformer-x.github.io/paper.pdf
RT-X Overview
The key feature of the RT-X model is its ability to leverage a massive dataset for training and transfer learning, thereby enhancing the performance and generalization capabilities of various robots. In experiments, the authors tested RT-X on six different robots, comparing its performance with models trained using original methods and single datasets.
They discovered that the RT-X model achieves positive transfer and the emergence of new skills. Furthermore, a significant characteristic of the RT-X model is its capacity to utilize experiences from other platforms to improve the capabilities of multiple robots.
This implies that knowledge and skills learned on one robot can be transferred to others, thus enhancing the performance of multiple robots. This is a crucial feature as it implies that by training a model on a large-scale dataset, it can be applied to a diverse range of robots, significantly improving the efficiency and effectiveness of robot learning.
In summary, the RT-X model is a highly potent and adaptable robot control model, capable of handling a wide variety of tasks and adapting to various environments. By using this model, we can greatly enhance the efficiency and effectiveness of robot learning and control.
The experiments in this paper are based on two Transformer-based robot policies: RT-1 and RT-2.
RT-1 is an efficient Transformer architecture designed for robot control, while RT-2 is a large-scale visual-language model that can jointly fine-tune output robot actions as natural language representations. Both models take visual inputs describing tasks and natural language instructions, and output tokenized actions. For each model, actions are divided into 256 bins uniformly distributed along eight dimensions; one dimension is used for ending episodes, and the remaining seven dimensions control the movement of the end effector.
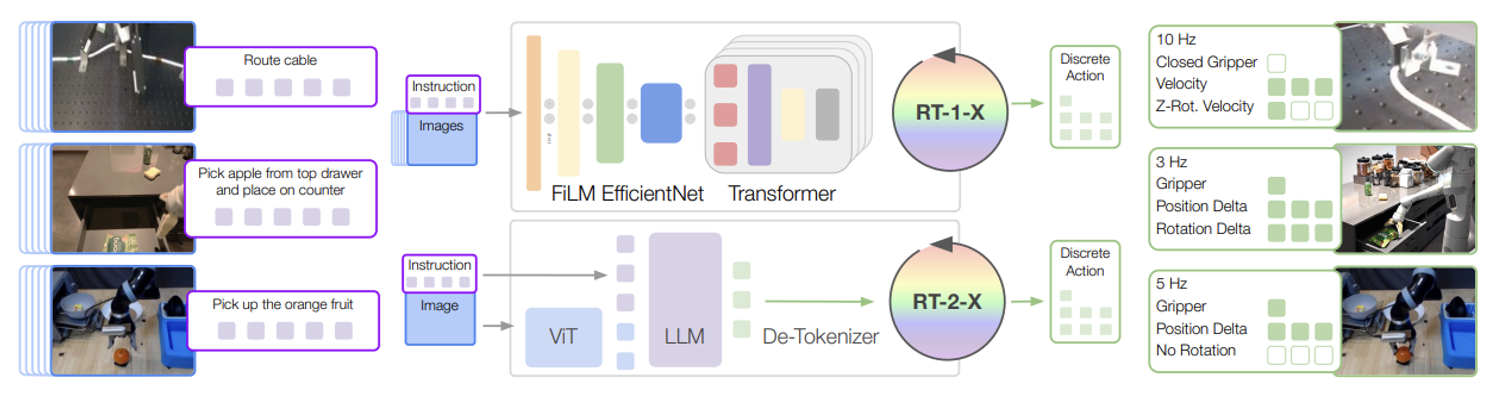
As shown in the above figure, RT-1 takes in 15 images and historical natural language data. Each image is processed through ImageNet pre-trained EfficientNet, and natural language instructions are transformed into USE embeddings. Visual and language representations are intertwined through FiLM layers, generating 81 visual-language tokens. These tokens are fed into a Transformer decoder, which outputs tokenized actions.
RT-2 further converts these tokenized actions into text tokens, for example, an action might look like "1 128 91 241 5 101 127." Consequently, any pre-trained visual-language model (VLM) can be fine-tuned for robot control, utilizing the VLM backbone and transferring some of its generalization capabilities. This work focuses on the RT-2-PaLI-X variant, built on the ViT visual model and the UL2 language model backbone, with primary pre-training conducted on the WebLI dataset.
Highlights of RT-X
Large-scale Dataset: RT-X model's training data originates from a massive dataset in robot learning, collaboratively collected by 21 organizations. This dataset encompasses over 1 million trajectories from 22 different robots, showcasing 527 different skills. This extensive dataset provides RT-X with a wealth of training samples, enabling the model to learn a wide variety of skills and knowledge.
Transfer Learning: RT-X model can leverage this extensive dataset for training and transfer learning, thereby enhancing the performance and generalization capabilities of various robots. Knowledge and skills learned on one robot can be transferred to others, thus improving the performance of multiple robots.
In summary, the RT-X model achieves strong generalization and robustness through the utilization of large-scale datasets for training and transfer learning.
Limitations and Future Development
While RT-X represents a step towards the vision of X-embodied universal robot learners, there are further steps needed to realize this future. Our experiments have some limitations: they do not consider robots with vastly different perception and execution modes, do not explore the generalization to new robots, and do not provide a decision criterion for assessing positive transfer. Addressing these issues is an important direction for future research.



