
Gemini Outperforms ChatGPT 4: Next Steps in Niche Markets?
Release time:2023/12/21
Back list
Gemini is Google's latest LLMs, first revealed by Google CEO Sundar Pichai at the I/O developers conference in June, and is now being rolled out to the public. Gemini was built from the start as a multimodal model, meaning it can generalize and seamlessly understand, manipulate, and combine different types of information, including text, code, audio, images, and video. In terms of flexibility, it can operate everywhere from data centers to mobile devices.
Gemini is not just a single artificial intelligence model. There is a lighter version called Gemini Nano, designed to run offline locally on Android devices. There is a more powerful version named Gemini Pro, which will soon support many Google AI services and, starting today, becomes the backbone of Bard. There is also an even more powerful model called Gemini Ultra, which is the most powerful Master of Laws that Google has created so far, seemingly designed mainly for data centers and enterprise applications. Gemini Nano may completely revolutionize the current voice assistants on various endpoint devices.

The Gemini architecture
While the full details have not been disclosed by Google's researchers, the report of Gemini mentions that it is built upon the Transformer decoder. It has undergone architectural and model optimization improvements for large-scale, stable training. These models are written in Jax and trained using TPU. The architecture resembles DeepMind's Flamingo, CoCa, and PaLI, featuring separate text and visual encoders.
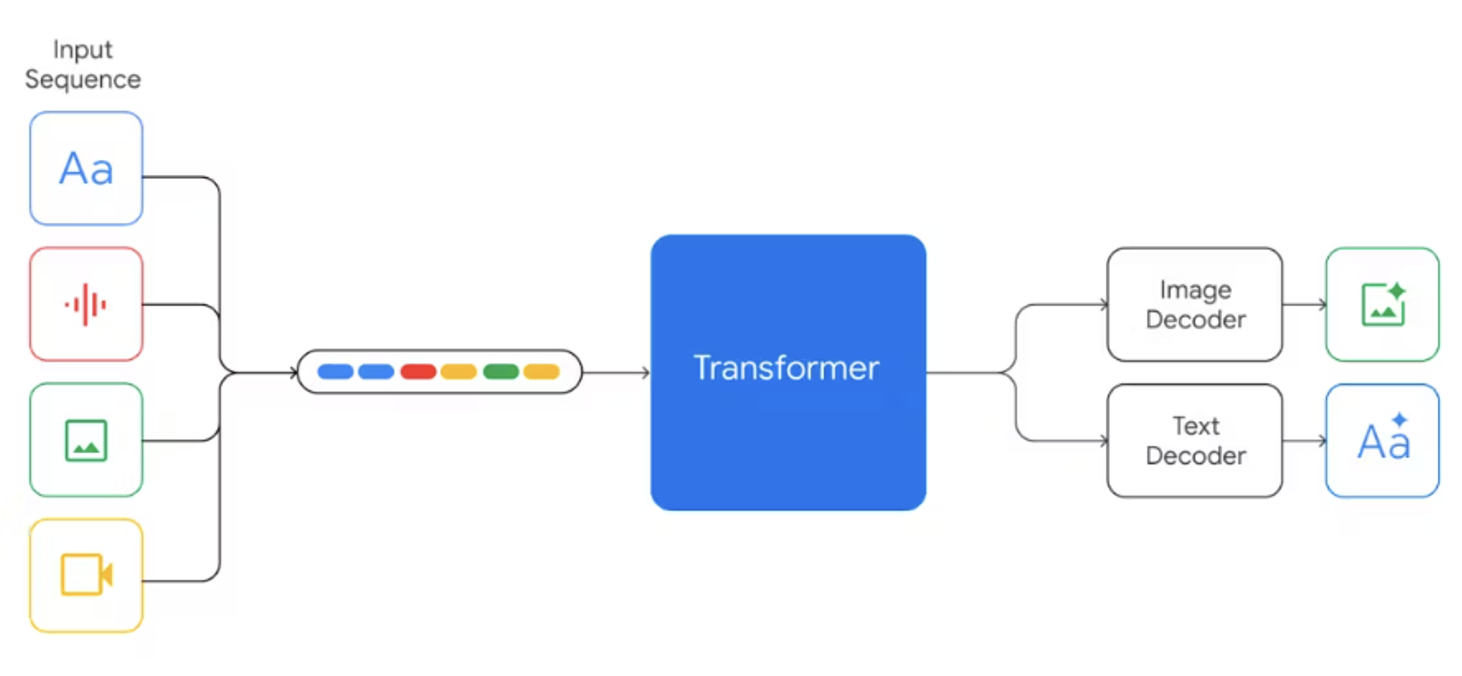
From'Gemini: A Family of Highly Capable Multimodal Models'
Next Steps in Niche Markets
Since ChatGPT exploded on the internet, LLMs have emerged rapidly. Many internet giants have joined the competition of open-sourcing LLMs. This presents both challenges and opportunities for our developers and other industries.
Artificial intelligence is accelerating the development of various industries, but its actual implementation faces many challenges. Although Whisper, ChatGPT, and Gemini can recognize many languages, there are a total of 5,651 human languages, with India alone having over 150 languages and the indigenous languages of the Americas exceeding 1,000.
To truly serve everyone with artificial intelligence, it is essential to migrate the general-purpose base models to various practical application scenarios or different language environments. For example, in voice synthesis, common languages like English, Chinese, Japanese, and Korean have matured significantly, thanks to their rich language corpora. However, for smaller European languages like Dutch, Bulgarian and Serbia, the synthesis results are less impressive. Therefore, collecting and expanding the language corpora of these smaller languages is a crucial step in implementing general-purpose voice models in countries where these languages are spoken natively.
Speech Synthesis Data for Minority Languages
In response to the challenge of applying universal models in different countries and regions and serving everyone, the company DataOceanAI actively promotes the collection, recording, and annotation of data for lesser-spoken languages. We possesses a vast amount of rare language data for voice synthesis and recognition, covering numerous application scenarios, various styles, and precise annotations.
- Dutch Female Synthesis Corpus King-TTS-262 >>>Learn more
- Swedish Male Speech Synthesis Corpus King-TTS-060 >>>Learn more
- Finnish Female Speech Synthesis Corpus King-TTS-075 >>>Learn more
Reference
https://deepmind.google/technologies/gemini/#hands-on



