
CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data
Release time:2024/01/24
Back list
Title: CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data
Affiliation: Facebook AI
Authors: Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary,
Francisco Guzman, Armand Joulin, Edouard Grave
Pdf :https://arxiv.org/pdf/1911.00359.pdf
Overview
Pre-trained text representations have achieved significant accomplishments in many areas of natural language processing. The quality of these pre-trained text representations is greatly influenced by the size and quality of the pre-training corpus. In this paper, we describe an automated process for extracting large-scale, high-quality monolingual datasets in multiple languages from Common Crawl. Our process follows the data processing method introduced in fastText (by Mikolov et al., 2017; Grave et al., 2018), which includes deduplicating s and identifying their languages. We also enhance this process by adding a filtering step to select s that are close to high-quality corpora such as Wikipedia. The main purpose of this work is to improve the effectiveness of pre-trained models.
Method
In this paper, we propose a data collection process that can gather large-scale, high-quality monolingual corpora in multiple languages, including many resource-poor languages. Our process principle is universal, and we demonstrate its application to data collected by the Common Crawl project. Common Crawl is a large-scale, non-curated dataset of web pages in many languages, mixed together in the form of time snapshots. Our process performs standard deduplication and language identification, similar to the method of Grave et al. (2018), but with two distinctions: First, we preserve -level structure to enable training of paragraph-level representations like BERT (by Devlin et al., 2018); second, we add an optional monolingual filtering step to select s close to high-quality sources such as Wikipedia. This is achieved by training a language model on the target source and using perplexity as the 's scoring function. Our process can be applied to any number of Common Crawl snapshots, and each snapshot processing requires 8.5 hours, running on 5000 CPU cores. For example, the dataset obtained by preprocessing the February 2019 snapshot includes 1.5 billion s in 174 languages. There are over 700 million filtered s in English alone, corresponding to 532 billion tokens. This is 120 times larger than the data used by Devlin et al. (2018).
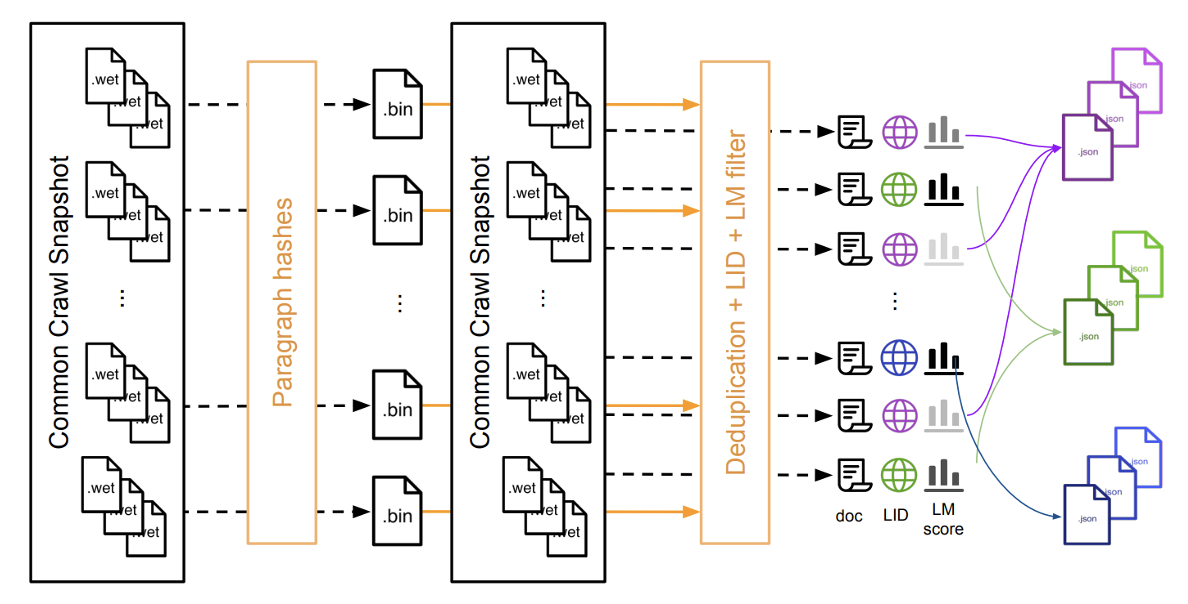
Figure 1: We present the entire process of downloading and processing a snapshot of Common Crawl.
First, we download all the WET files, calculate the hash values of paragraphs, group them, and save them in a binary file. Then, we process each in the WET files independently: we deduplicate paragraphs using the binary file, perform language identification, and calculate the perplexity scores of the language model. Finally, we reassemble the s into JSON files d on language and perplexity scores. Steps in the process indicated by dashed arrows can be executed in parallel. Below is the algorithm execution process:
- Preprocessing
Each snapshot contains about 20 to 30 TB of uncompressed plain text, corresponding to approximately 3 billion web pages (for example, the February 2019 snapshot contains 24 TB of data). We download and process each snapshot independently. For each snapshot, we group WET files into fragments of 5 GB each. For the February 2019 crawl, this resulted in 1600 fragments. These fragments are saved in a JSON file, where each entry corresponds to a webpage.
- Deduplication
The first step in the process is to remove duplicate paragraphs between different web pages in the snapshot, as they account for 70% of the text. We first normalize each paragraph by converting all characters to lowercase, replacing numbers with a placeholder (i.e., 0), and removing all Unicode punctuation and diacritical marks. Deduplication then consists of two independent steps. First, for each fragment, we calculate a hash code for each paragraph and save them in a binary file. We use the first 64 bits of the SHA-1 number of the normalized paragraph as the key. Then, we deduplicate each fragment by comparing it with a subset or all binary files. The impact of this choice is discussed in Section 4. These steps are independent for each fragment and can therefore be executed in parallel. In addition to removing web page duplicates, this step also removes many trivial items such as navigation menus, cookie warnings, and contact information. Specifically, it removes a large amount of English content from web pages in other languages, making the next step of our process, language identification, more robust.
- Language Identification
The second step of the process is to split the data by language. Like Grave et al. (2018), we use the language classifier in fastText (Joulin et al., 2016b; Grave et al., 2018). The fastText language identifier is trained on Wikipedia, Tatoeba, and SETimes. It uses character n-grams as features and a hierarchical softmax. It supports 176 languages and outputs a score in the range of [0,1] for each language. It processes 1000 s per second on a single CPU core. For each webpage, we compute the most likely language and the corresponding classifier score. If the score is above 0.5, we classify the in the respective language. Otherwise, the language is not clearly defined, and we discard the corresponding page.
- Language Model Filtering
In this step of the process, there are still s with lower quality content. One way to filter out these samples is to compute a similarity score of the web page to a target domain (such as Wikipedia). In this paper, we suggest using the perplexity of a language model trained on the target domain as a quality score. Specifically, for each language, we train a sentence piece tokenizer (Kudo, 2018) and a language model, using the 5-gram Kneser-Ney model implemented in the KenLM library (Heafield, 2011), as it is efficient in handling large amounts of data. Then, we tokenize each page in the dataset using our sentence piece tokenizer and calculate the perplexity of each paragraph using our language model. The lower the perplexity, the closer the data is to the target domain. At the end of this step, each language is divided into three parts: the head, middle, and tail, corresponding to the perplexity scores. In Section 5, we show the perplexity distribution of a Common Crawl snapshot. We have trained sentence pieces and Kneser-Ney language models for 48 languages on Wikipedia. We make these models publicly available in the repository. If users wish to filter Common Crawl with other data, we also provide code to train sentence pieces and Kneser-Ney language models and to compute terciles thresholds.
- Reproducing Results Without the Process
Rebuilding the dataset by running our process requires substantial resources and time. Along with the release of the process, we provide a tool that can effectively reproduce the results of this work. This tool is d on a file containing URLs of web pages and reconstructs the final output of our process from that file.
Ablation Study
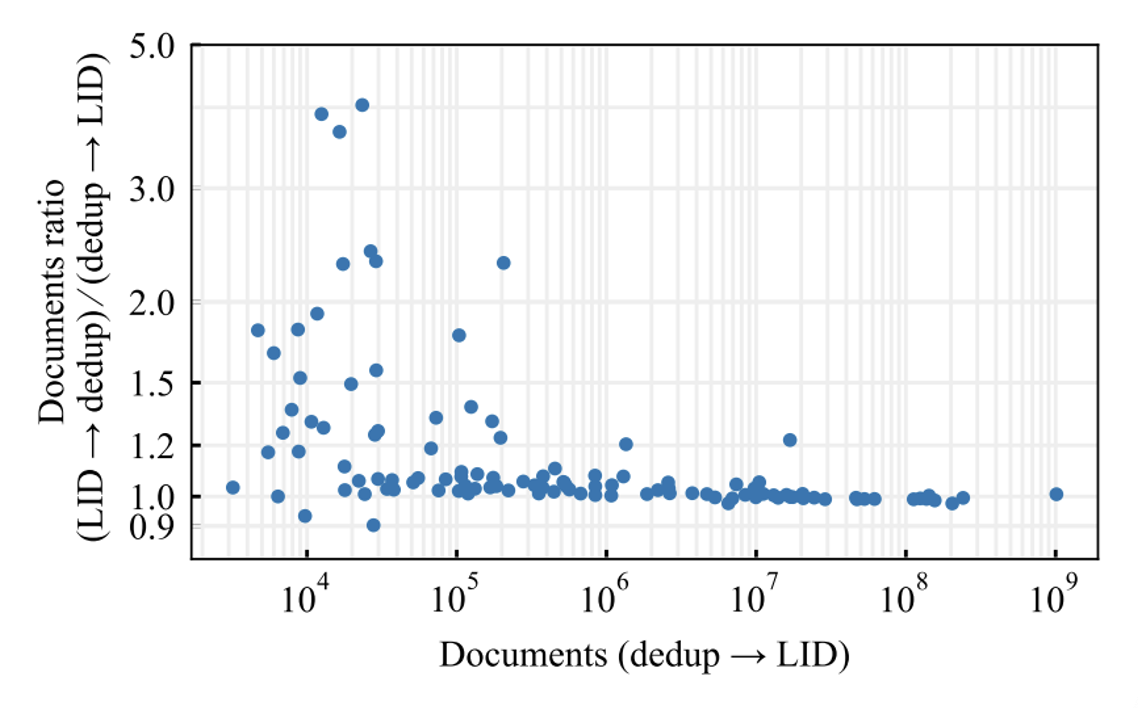
Figure 3: Demonstrates the impact of the 'Deduplication then LID (Language Identification)' versus 'LID then Deduplication' on the resultant dataset. The Y-axis shows the ratio of the number of s in each language between the two methods. The X-axis is the number of s in each language obtained after deduplication using LID scores. Languages with fewer resources benefit more from the 'Deduplication then LID' approach. These statistics are estimated on 1% of the February 2019 snapshot.
- Order of LID and Deduplication Steps
Unlike Grave et al. (2018), we choose to deduplicate data before language identification, as many pages in other languages contain a lot of English noise, such as cookie warnings. Deduplication removes a large amount of noise data, enabling better language identification. This is particularly important for some languages with fewer resources. In Figure 3, we report the relative increase in the number of s when using 'Deduplication then LID' instead of 'LID then Deduplication'. We observed that many s in low-resource languages were misclassified (usually as English) or discarded due to unrecognizable language before deduplication.
- Impact of Deduplication Volume
For deduplication, we can compare paragraph hashes within each fragment, across a span of fragments, or the entire snapshot (1600 fragments). The larger N, the more s are removed, and the more RAM is used by the algorithm. In Section 4, we show the remaining data volume (as a percentage of character count) after deduplication of a fragment from the February 2019 snapshot, spanning 1, 2, 5, 10, 20, 50, and 100 fragments. After spanning 1 fragment, 42% of characters remain; after 100 fragments, 28% remain. Loading hash values from 50 fragments represents 1.5 billion unique hashes, occupying 13.5 GB of disk space. Using memory-efficient hash sets, we can fit them in 40 GB of RAM. In Section 5, we show how RAM increases when we try to load more hash values into memory. We found 50 fragments to be a reasonable compromise, hence currently running deduplication on blocks occupying 3% of the corpus.
- Benchmarking
The process is massively parallelizable, but due to the need to compare billions of paragraphs, it still must be run in two steps. In our case, we chose 5~GB fragments as the smallest unit of parallelization. A snapshot is divided into 1600 fragments, each containing about 1.6 million s. Computing paragraph hashes processes about 600 s per second on one CPU core while downloading files. This means completing a fragment containing about 1.6 million s in approximately 45 minutes. We compute all hashes on 1600 CPUs in 45 minutes. In one pass, the next step will remove duplicates, and perform language identification, sentence piece tagging, language modeling, and language- d splitting. Each fragment creates three files for our first 48 languages with LM, and for other languages without LM, we have only one file. These processes require a lot of RAM, but memory can be shared between processes as it is read-only. This step is much longer than the previous one. We allocate 17 processes for a fragment. The main process is responsible for downloading data and distributing raw s to 16 worker threads, while writing results to disk. Worker threads process about 40 s per second, completing an entire fragment in about 40 minutes. Removing duplicate paragraphs takes up 40% of the time. This step is computationally cheaper but applies to all data, unlike the next step which only applies to deduplicated data. The language identifier occupies 12.5% of CPU time, sentence pieces 33%, and LM 13%. Finally, we regroup the files generated in the previous steps into blocks of 5GB each. This can run in parallel, and for each output file, it is very fast, taking only a few minutes, because gzip archives can be directly concatenated without needing to decompress first. For a snapshot, the total processing time using 5000 CPU cores is about 9 hours.
Metrics About The Resulting Dataset
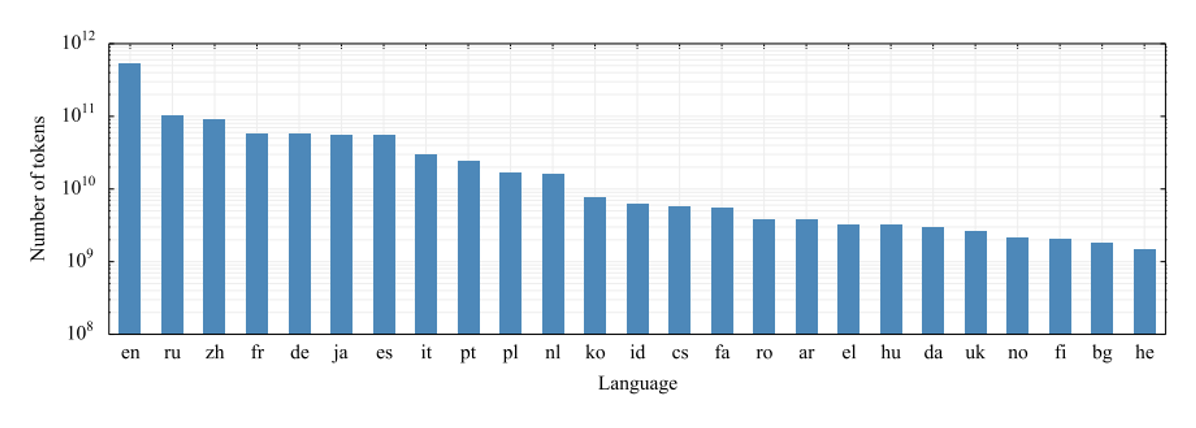
Figure 2 Number of tokens per language for February 2019 snapshot after deduplication. We display the histogram on a logarithmic scale.
- Statistics from Language Models
We find that perplexity is a relatively good proxy for quality. News and well-written content end up at the head of our dataset. Some s contain long lists of keywords, surviving deduplication and LID, but receive high perplexity. Some s, while being valid text, end up at the tail because their vocabulary is very different from Wikipedia. This includes blog comments with colloquial text, or highly specialized forums with specific jargon. We decided not to delete content d on LM scores, as we believe some of this content might be useful for specific applications.
The perplexity distribution for some languages is very peaked, while for others it is more dispersed. We assume this is more due to the size differences of the Wikipedias used for training the LMs, rather than certain languages having less high-quality content. Therefore, we decided to use different perplexity thresholds for each language. Thresholds were chosen to divide the corpus into three equally sized parts.
- Training Models on This Dataset
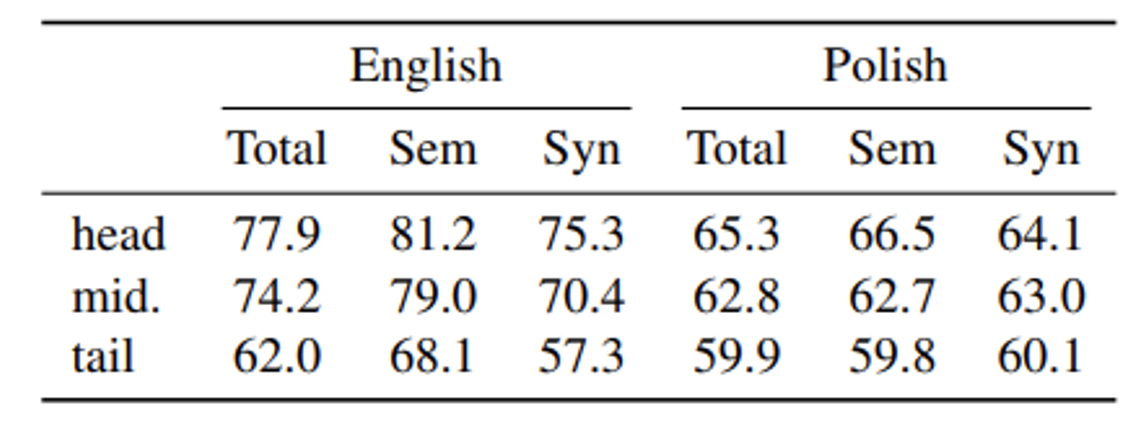
We evaluate the quality of the resulting dataset by learning unsupervised word and sentence representations with fastText and BERT models on this dataset. For fastText, we train 300-dimensional word dings on the head, middle, and tail subsets of the English and Polish Common Crawl corpus sorted by perplexity. We evaluate these models on standard semantic and syntactic analogy datasets. In Table 1, we observe a steady improvement in performance as we move from the tail to the head of the dataset, confirming the positive impact of filtering d on perplexity.
Table 1: Impact of corpus quality on fastText word ding quality. We evaluate on semantic and syntactic similarity datasets.
We also trained BERT models in languages like English (en), Russian (ru), Chinese (zh), and Urdu (ur), using either the Wikipedia corpus or our new CommonCrawl dataset. For these languages, we used 16G, 5G, 1.1G, and 106M of raw Wikipedia data (the full dataset), respectively, and augmented the head CommonCrawl data to 21G, 21G, 17G, and 2.2G for English, Russian, Chinese, and Urdu. That is, we used roughly the same amount of data for English but increased the data volume for Russian, Chinese, and Urdu. We trained the BERT- architecture (Devlin et al., 2018) on each corpus without Next Sentence Prediction (NSP, following the method of Lample and Conneau, 2019). For a fair comparison, we stopped each model after training for two days and used the exact same number of steps for each model. We evaluated using the XNLI (Conneau et al., 2018) corpus on the training data of each language. The results presented in Table 2 show that on average, the performance of BERT- models trained on CommonCrawl is superior to the same models trained on Wikipedia. For English, using the same amount of data, our corpus-trained BERT- model outperforms the model trained on Wikipedia. For low-resource languages like Urdu, the Wikipedia dataset is too small, thus models pre-trained on Wikipedia achieved similar performance to randomly initialized models. However, using our corpus, we achieved a 7-percentage point increase in accuracy, indicating that our filtered corpus can facilitate language model pre-training for low-resource languages.
Conclusion
In this paper, we presented a pipeline for creating curated monolingual corpora in over 100 languages. We preprocessed Common Crawl by following the process of Grave et al. (2018), but unlike them, we preserved the structure of s and filtered data d on their proximity to Wikipedia. This improved the quality of the generated datasets and allowed for the training of multilingual text-level representations, such as XLM (Lample and Conneau, 2019).
Reflection and Thinking
In the current field of artificial intelligence, the training of large models often relies on massive data scraped from the internet. While this approach can provide a wealth of learning material for the models, it also brings several risks. Firstly, the quality of data obtained from web scraping is uneven, inevitably containing incorrect, outdated, or even harmful information, which can affect the accuracy and reliability of the models. Secondly, these data may involve privacy and copyright issues, and their legality and compliance cannot be guaranteed. Using such data could lead to legal and ethical disputes.
In contrast, professional data companies like DataOceanAI offer significant advantages with their safe data. Firstly, their data is usually annotated and reviewed by professionals, ensuring accuracy and reliability. Secondly, professional data companies rigorously select and manage their data sources, ensuring the legality and compliance of the data, greatly reducing legal and ethical risks. Additionally, these companies can customize data according to the specific needs of projects, providing more personalized and targeted data services.
Therefore, choosing safe data provided by professional data companies is particularly important when training large models. This not only improves the learning efficiency and accuracy of the models but also ensures that the training and application of the models do not violate legal and ethical boundaries. In a data-driven era, high-quality, high-security data is key to achieving healthy, sustainable development in artificial intelligence.
References
Wenzek, Guillaume, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, and Edouard Grave. "CCNet: Extracting high quality monolingual datasets from web crawl data." arXiv preprint arXiv:1911.00359 (2019)."



